
解説●松尾直樹
筆者プロフィール
大阪にてポスプロ勤務後、現在はフリーランスとして東京・大阪を中心に活動。DaVinci Resolveをメインに使用している。他に専門学校大阪ビジュアルアーツアカデミーにて、講師として編集を教える授業も行なっている。
AIを使った音声調整機能をふたつ紹介
先日発売になった「仕事で使える! DaVinci Resolve講座」では、直前で間に合ったVer.20の情報も入れ込んでいます。印象的だったのが即戦力が期待される音声関係の新機能群です。ここでは紹介できなかったAIを使ったふたつの音声調整機能、「音声変換」と変換用に使用する「DaVinci AI音声トレーニング」、音声トラックを自動で調整するAIツール「オーディオアシスタント」について解説します。
済1.エディットページのキーフレームエディター
済2.マルチカムの自動スイッチング
済3.スムースカットの進化
済4.マルチテキスト追加
5.ボイス変換
6.AIオーディオアシスタント
7.字幕の文字装飾
8.マジックマスク2
9.クロマワープ
10.Fusionで最終結果表示
11.Blackmagic Designクラウドの機能拡張
12.カスタム書き出しをクイックエクスポートに追加
番外編:WindowsでのProRes出力
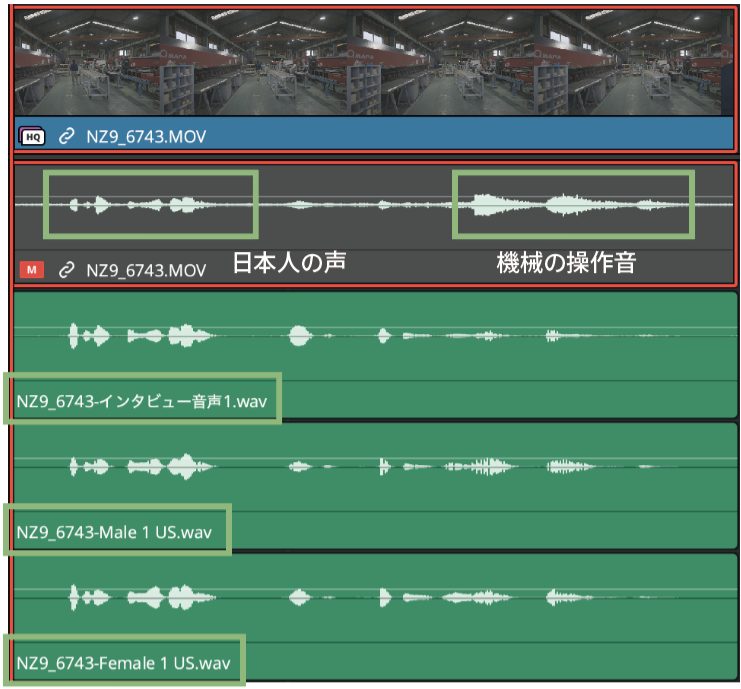
エディット/Fairlight 別の人物の声に変えられる「音声変換」
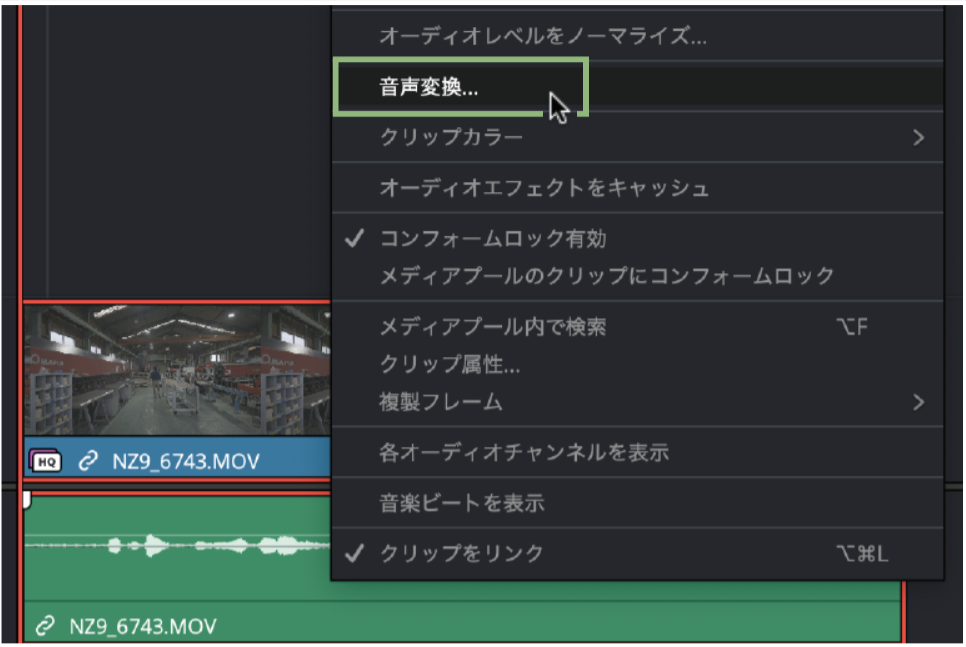
今回のアップデートの中で大きな機能追加のひとつが、人物の声を別の人の声と差し替える「音声変換」機能です。誌面では変換した音声をお届けできないのが残念ですが、AIにより話し声を別人または本人の学習データで置き換えることができます。実際に試してみないと伝わりにくいと思いますが、最近VTuber等で流行の「AIボイスチェンジャー」のような機能だと思ってもらえればよいかと思います。
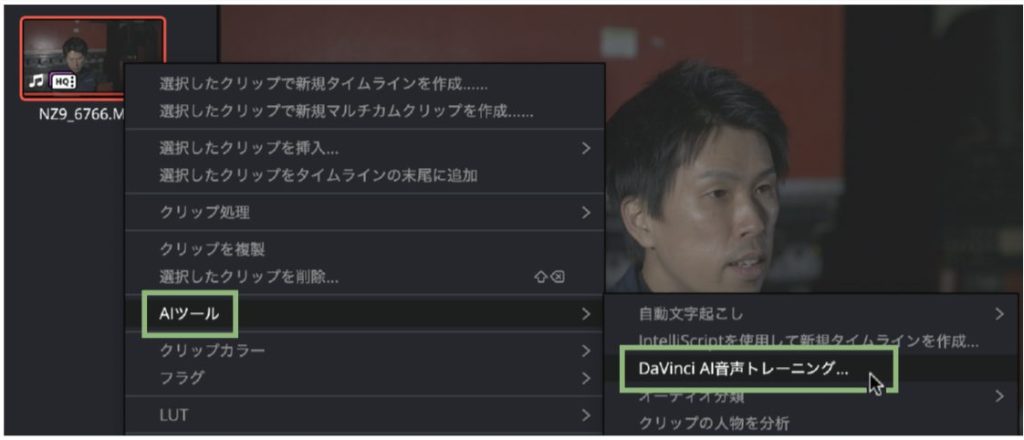
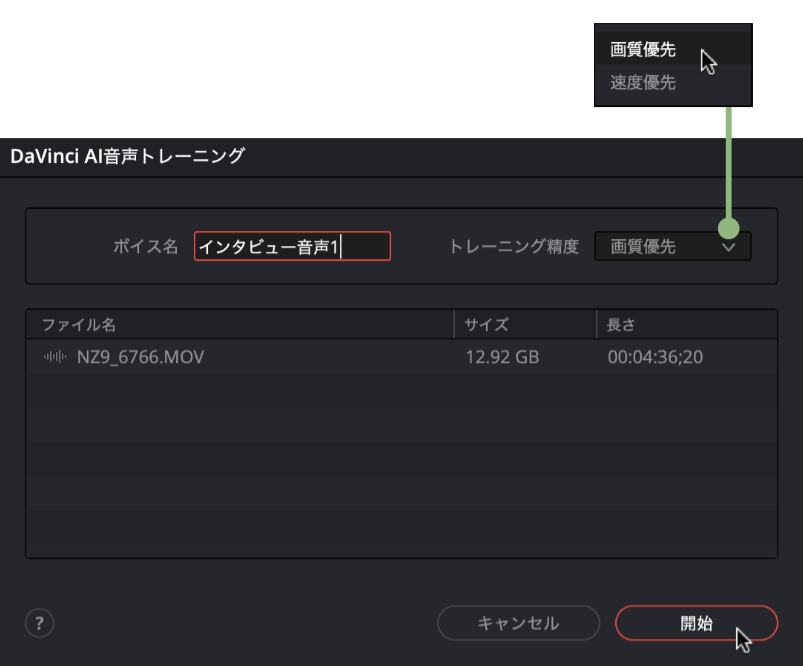
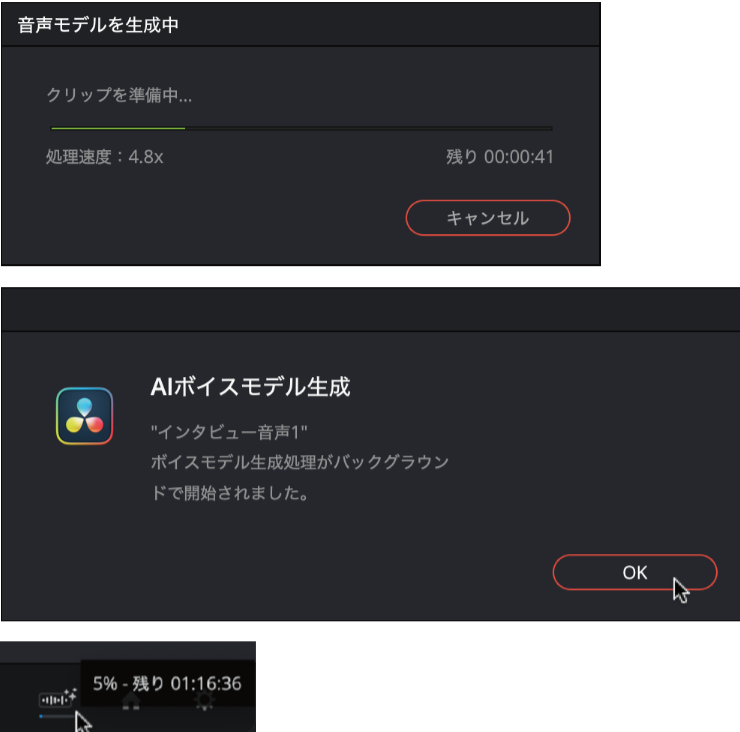
この機能の面白いところは、DaVinci Resolveに特定の人の声を学習させ、それを「音声モデル」として登録し、変換することができるということです。音声モデルを作成するために使用するのが「DaVinci AI音声トレーニング」機能。変換に使用したい人物、もしくは本人の音声データをアップロードするだけで生成することができます。
この機能が役立ちそうだと私が思うのは、インタビューした人の声を学習させて、その人の声で同じ人の声を置き換えることができる点です。一見無意味なことに思えますが、背景ノイズが酷い場合などに、ノイズのないクリーンな音声に変換することも可能になります。強力なノイズリダクションとして捉えると使いどころが多そうです。
ただし、学習させる音声、この場合ならインタビューで話している動画の尺が短いと学習が上手くいきません。理想は1時間程度らしいので講演会等なら現実的です。マシンパワーも必要になり、1時間の学習で処理が完了するのに18時間は見ておいたほうがよいでしょう。
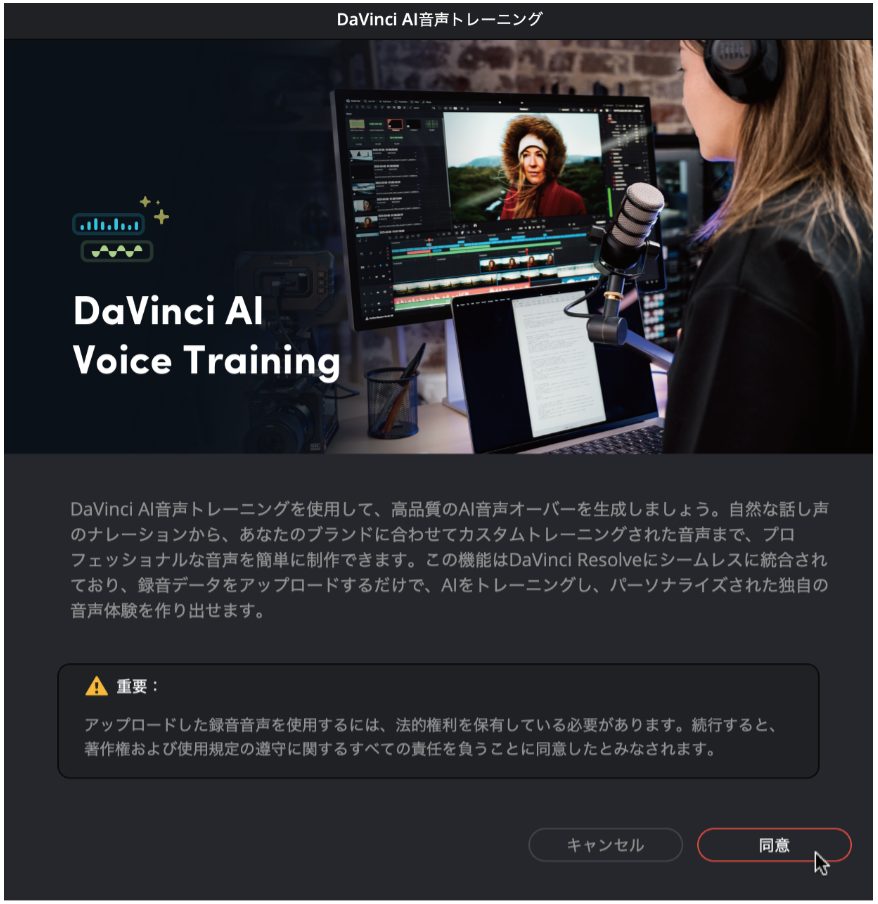
また、学習させる音声の著作権に配慮する必要があります。「DaVinci AI音声トレーニング」を起動するときに「重要」な警告として「アップロードした録音音声を使用するには、法的権利を保有している必要があります。続行すると、著作権および使用規定の尊守に関するすべての責任を負うことに同意したとみなされます」と注意を促しています。
操作手順❶「DaVinci AI音声トレーニング」で音声モデルを生成
↓
↓
↓
↓
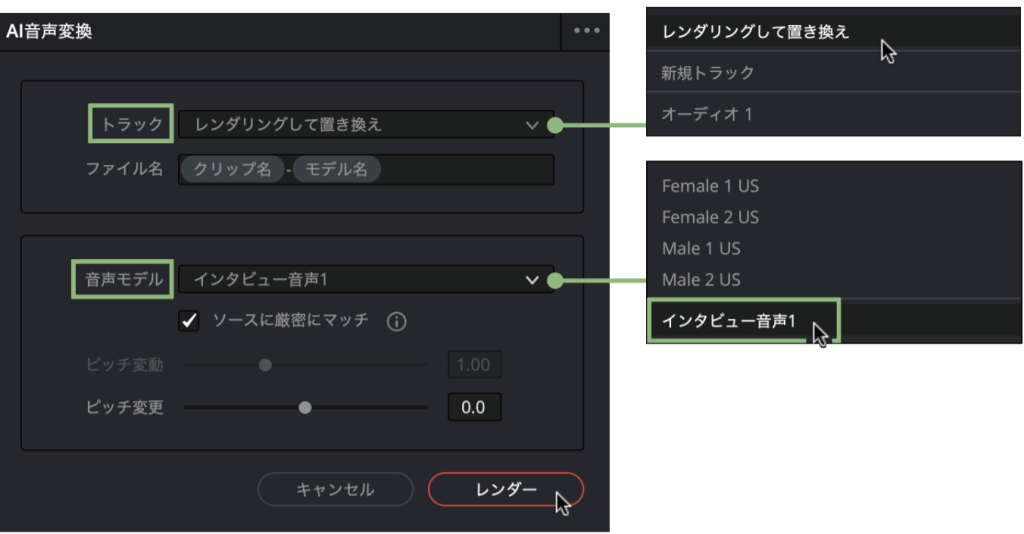
操作手順❷「音声変換」を実行する
↓
↓
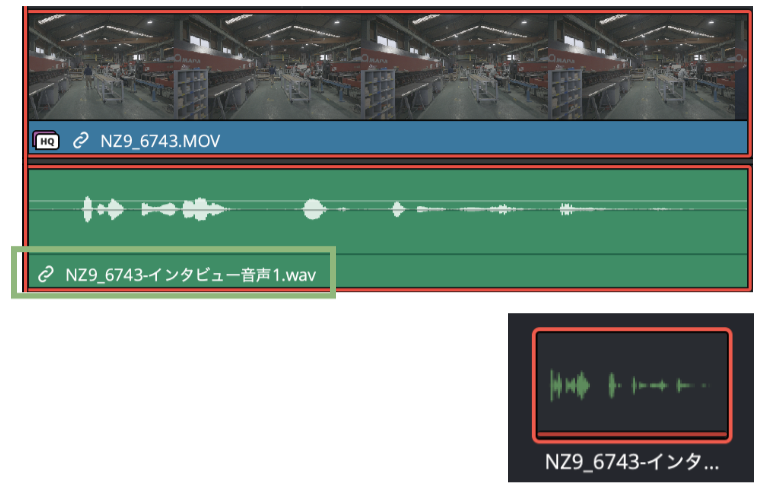
❸「レンダリングして置き換え」を選択すると生成した音声が、オリジナルクリップの音声に置き換わる。クリップ名の後にモデル名が付く。生成した音声クリップはメディアプールにも登録される。
↓

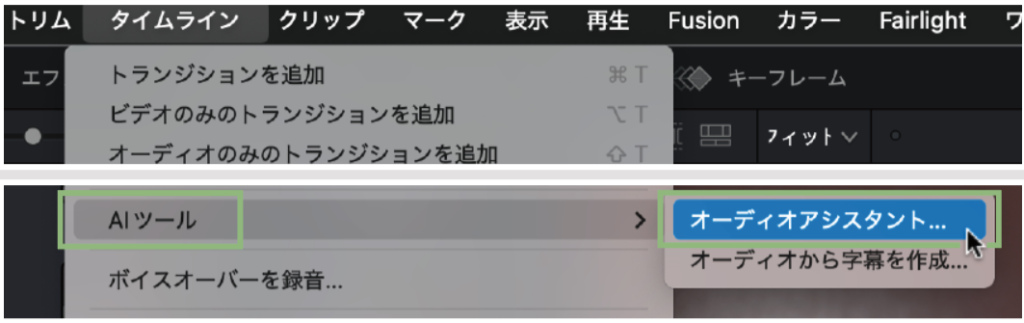
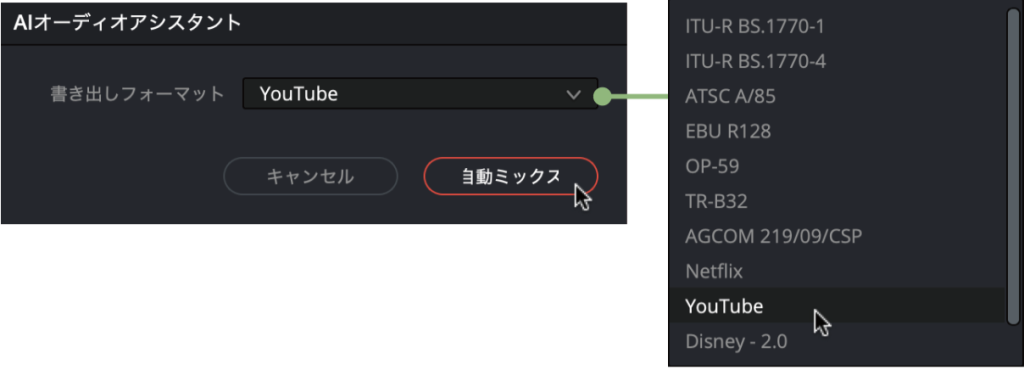
配信先に合わせて音声を自動調整「AIオーディオアシスタント」
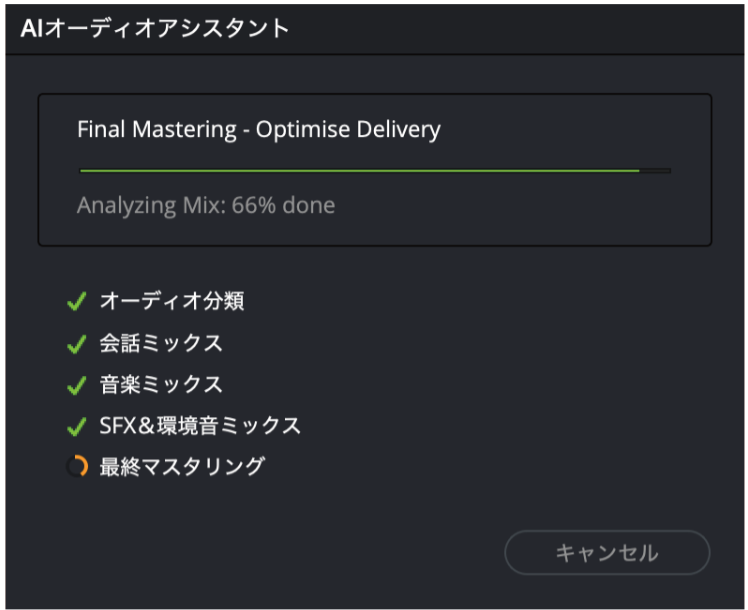
「AIオーディオアシスタント」機能を使うと、完成したタイムラインの音声トラックを自動で整理してくれます。ダイアログを開くとデフォルトではYouTube向けの設定になり、実行すると「オーディオ分離」、「会話ミックス」、「音楽ミックス」、「SFX&環境音ミックス」、「最終マスタリング」という5つの処理を順番に行なっていきます。
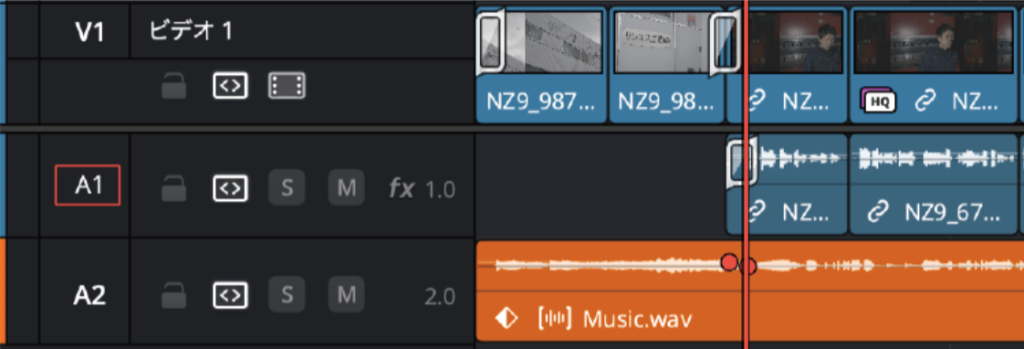
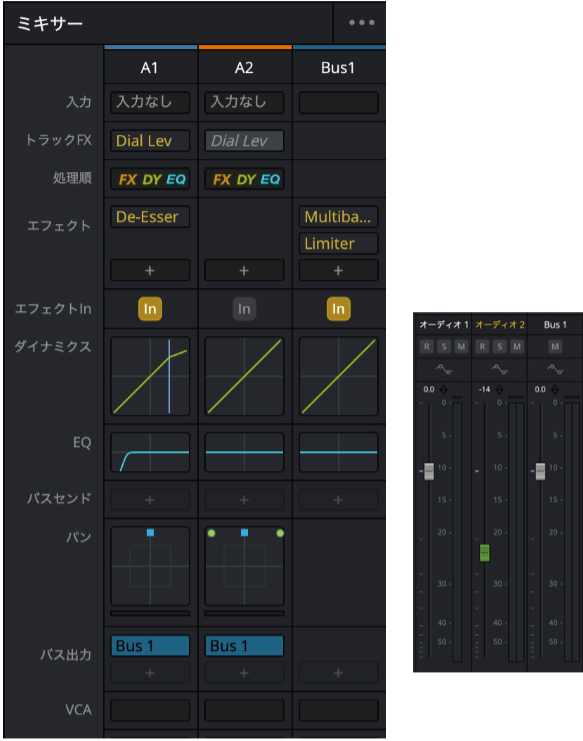
終了後にFairlightページで確認すると、EQやフェーダー、各種プラグインが設定され、各トラックの音量、声の低音カット(EQ)など、トラックに入った音声から推測して自動で調整されているのが分かります。また音声トラックには別のトラックカラーが設定され、色分けも行なってくれます。
「AIオーディオアシスタントを実行すればそれで完成」というわけにはいきませんが、整えやすいように仕込んでくれるので、声、BGM、環境音のミックスレベルを調整するような仕事であれば工数を削減できます。
↓
↓
↓
【最新刊のご案内】
仕事で使える! DaVinci Resolve講座 実際の映像制作を想定した実例で学ぶ

筆者の松尾氏が行なったVIDEO SALONウェビナー「仕事で使えるDaVinci Resolve〜プロモーションムービーを実例に効率的な編集テクニックを1カ月でマスターする!」をVer.20を使用しながら再構成して書籍化しました。
7月22日発売/本体3,000円+税
