生成AIツールを使った画像出力
プロンプトを入力すると内容に合わせて画像が生成される
同じプロンプトで画像生成をしてもアウトプットされるものは常に変化する
生成AIにはさまざまなツールが存在しており、まったく同じプロンプトで画像生成をしてもアウトプットされるものは変わります。ここでは、代表的な生成AIツールであるStable Diffusionの使い方を解説しつつ、「赤いドレスを着たひとりの女の子が森の中で笑っているイラスト」という意味のプロンプトを入力した場合、アウトプットとしてどのようなイラストが生成されるのかを解説していきます。
また、まったく同じプロンプトを別の各生成AIツールに入力した場合、どのような結果になるのかもあわせて比較していきます。

Stable Diffusionを使ったイラスト生成方法

● Stable Diffusionの画面
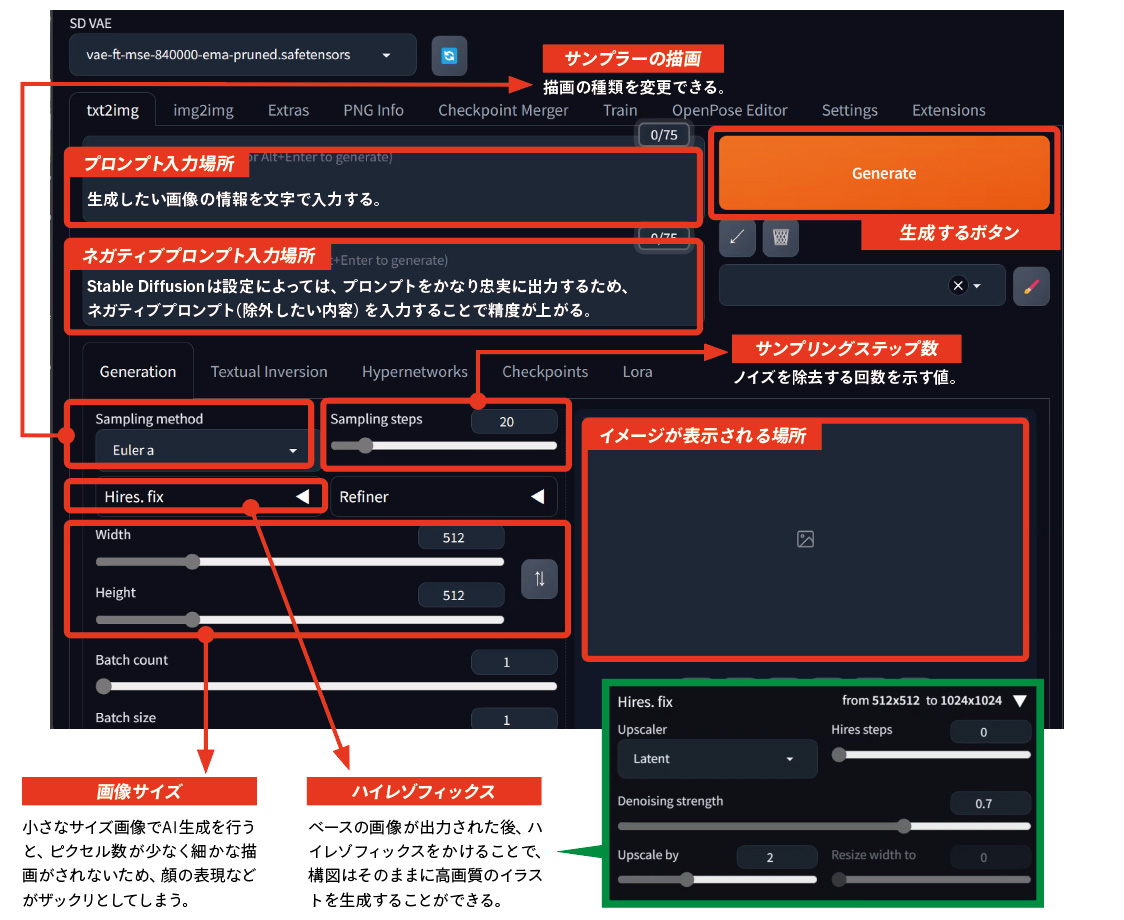
● Stable Diffusionを使ったイラスト生成手順
1:プロンプト入力欄にプロンプトを入力し、「Generate」をクリック。
プロンプトの文字情報は頭から順に読み取られるため、優先させる情報によって単語を並べ替えるのも効果的。

512×512サイズで生成出力されたイラスト。画像サイズが小さいため、顔の表情など細かな部分がザックリとした描写になっているのがわかる。

2:サンプラーの描画、サンプリングステップ数を調整する。

「Sampling method(サンプラーの描画)」を「DPM++2M SDE」に変更し、「Sampling steps」の値を20から60に引き上げて再度出力した画像。サンプリングステップの数だけ拡散モデルの復元過程の計算を繰り返し、ノイズを取り除いて質の高いイラストを生成することができる。

3:ネガティブプロンプトを入力する。

ネガティブプロンプト(画像生成する際にアウトプットに含めたくない要素)を入力し、指定した条件を除外。ここでは“低クオリティーのものをすべて除外する”という条件を指定。また、「EasyNegative」を導入することで、ネガティブプロンプト入力の負担を最小限に抑え、生成画像のクオリティを底上げすることができる。

4:ハイレゾフィックスで解像度を上げる。
「Upscale by」を2倍に設定し、画像サイズを512×512から1024×1024に拡大。「Denoising strength」は、「Hires.fix」機能で画像の拡大を行なった際にノイズを除去する強さを指す。
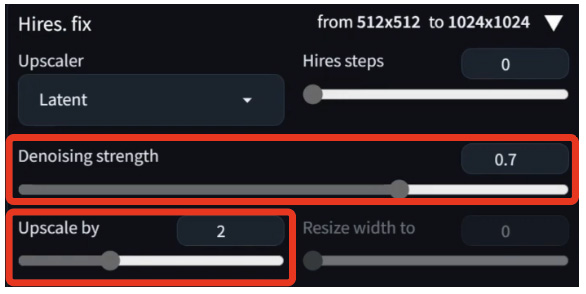
解像度が上がったことで描き込みの精度が格段に上がり、高精細な画像が出力された。

5:プロンプトを追加し、比率を調整する。
画面の大きさに対して顔が小さいため、顔の比率を上げるためのプロンプト「close-up」を追加。

最初に比べて全体的な密度が上がり、高精細な画像を生成することができた。「今回はテキストから画像を生成しましたが、手描きのラフスケッチから画像を生成することも可能です」と田中さん。

実際に田中さんがStable Diffusionでイラストを生成していく手順を動画でも確認してみよう。
● ネガティブプロンプトの有無を比較したStable Diffusionの生成AI画像
田中さんがStable Diffusionで生成した別パターンの生成画像。同じプロンプトで生成しても出力される画像は毎回異なる。また、ネガティブプロンプトの有無でクオリティにはかなり差が出るため設定には注意が必要。先の実例通り、かなり細かな設定ができる反面、設定を誤るとクオリティがまったく上がらないという結果にもなり得る。

同一プロンプトでの生成AIツール別出力画像比較
Midjourney」は、チャットツールDiscord上で動く生成AIツール。操作の手軽さとリアルな描写が特徴。

「niji・journey」は、Midjourneyをベースに作られた生成AIツール。2次元イラストに特化したツールとして人気が高い。

「DALL-E3」は、ChatGPTの開発元であるOpenAI社が開発している画像生成AI機能。テキストによる指示を元に画像を生成可能。

「Adobe Firefly」は、アドビ社が運営するストックサービスAdobe Stockを学習しているため商用利用が可能な生成AIツール。

動画生成AIツールの現状
プロンプトだけで納得のいく精度に到達するにはまだかなりの時間を要する
最近グッと進化してきているのが動画生成の分野で、静止画だけでなく動画をAIで生成することが可能になりました。主に、テキストから動画を生成するText to Videoと、指定した画像を動かすImage to Videoの2タイプがあります。Text to Videoの場合、テキストから動画を生成するためアウトプットのイメージがわきづらいのが難点ですが、Image to Videoの場合は元となる画像をベースに動かすことができるため、イメージしやすいという利点があります。ただ、どこをどう動かすかなど、細かい動きを指定することもできますが、激しく動かせば動かすほど破綻しやすくなりますし、プロンプトの指定だけでビデオグラファーや映像関係者が納得できるような精度に到達するには、正直まだかなりの時間を要するんじゃないかと思いますね。
現状では、絵をコントロールするための「ControlNet」というStable Diffusionで使える拡張機能などを組み合わせてキャラクターのポーズや構図を指定するなど、工夫を施すことでかなりの精度での生成をすることも可能ではあります。

先と全く同じプロンプトから生成した動画。指定したテキストから動画生成がされるため、 アウトプットイメージがつきづらいのが難点。

Stable Diffusionで生成した画像をもとに動画を生成。動きを細かく指定することである程度の制御ができる。
● 解説動画

A.
Stable Diffusionで生成する場合、ControlNetのReferenceもしくはIP-Adapterなどを使うことで比較的近しいものを出すことができます。ただ、完璧ではないので本当に固定したい場合は、LoRAで学習させて作ったほうが確実かと思います。

A.
Googleの画像検索を用いて類似物が世の中に出ていないかをチェックしています。もちろんすべてはチェックしきれませんが、「チェックをした」という証左を残すことが依拠性があるかどうかという観点で重要になるのではないかと考えています。

A.
まだ我々もしっかりと試せていないのですが、AnimateDiffとControlNetのIP-Adapterを使うのがもっとも作画崩壊しにくいですね。本当にごく最近出てきた新しい技術なので、興味があれば X (旧Twitter)などでぜひ検索してみてください。
クリエイターはAIにどう向き合うべきか?

過去に自分たちで作った『シキザクラ』というアニメ作品のとき、大人数を集めて作ること、それを継続していくことの難しさを思い知らされました。ただ、会社が少人数であっても僕らはアニメーションを諦めることはできないし、アニメーションを作り続けたいという想いがあります。では、僕らがやれる範囲でアニメーションを作っていくにはどうしたらいいのか、他社との差別化をどう図るべきか、今後どのようにアニメーションと向き合っていくべきなのか。そういった課題に対して、AIという存在を避けては通れないだろうと感じていました。僕らも日々いろいろな発見をしながら日進月歩で成長していくので、皆さんにもAIを活用してもらって、さまざまな発展や情報を経てAIがよりいいツールに進化していけばいいなと考えています。

クリエイティブの目線から言うと、CGやシンセサイザーが出たときと同じなんです。「AIが人間に取って代わるんじゃないか」と脅威を感じる人も多いかもしれませんが、あくまでもひとつのツールであって、全部が全部AIでやる必要はないですし、コミュニケーションをデザインするような部分はどこまでいっても人間が作ることになると思っています。AIの進化に合わせて、未来のアニメーションやクリエイティブはもちろん、世の中がより良くなっていけばいいですよね。

AIはとても便利なツールですが、それ故に社会に与えるインパクトや影響も大きいです。“AIアニメ”と謳うことでアニメ制作会社が矢面に立たされる現状があり、AI反対派の方からは「けしからん」という声が挙がることもあります。僕らの立場としては、できるだけ早くクリアな状態でAIを使える状況になることを国や政府に望みたいですね。従来の方法ではどうしてもやりたいことができなかったというクリエイターたちが、AIをうまく活用することによってもっと活躍できるようになればいいなと思っています。
【実演】30分でアニメ調のポスターを創ろう!


① niji・journeyを使い、「宇宙」をテーマにアニメテイストの画像を生成。
1: Discordのプロンプト入力欄にプロンプトを入力しEnter。生成コマンド「/imagine」を入力し、「1girl,universe,outer space,anime Cel shading」とプロンプトを入力。4種類の画像が生成される。
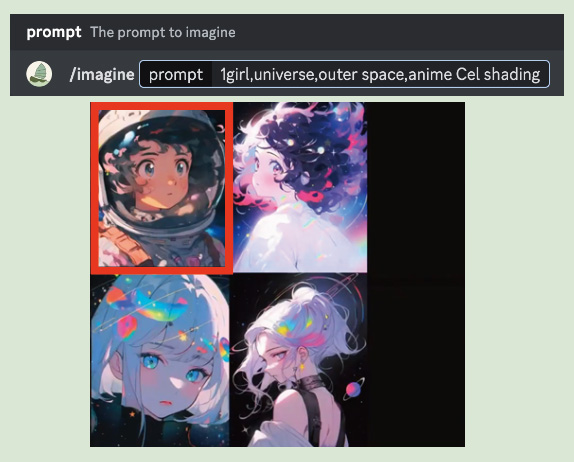
2: 左上の画像をベースに作り込むことを決定。「U1」をクリックし、高解像度の画像を生成。

「U1」〜「U4」を選択すれば指定した番号の画像を高解像度化し、「V1」〜「V4」を選択すれば指定した番号の画像と似たデザインのバリエーションを新たに4枚生成してくれる。
3: 選択した画像がアップスケールされて生成される。「zoom out 2x」「zoom out 1.5x」をクリックし、引いた画角の画像を生成、比較する。
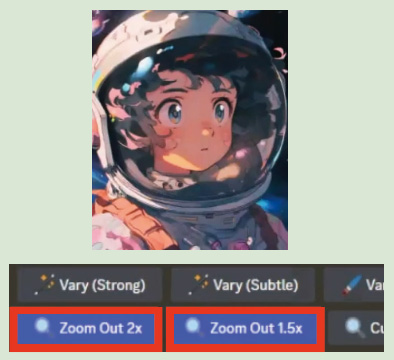
4: それぞれズームアウトした画像が生成。2倍ズームアウトした画像の中から「U2」を選択。


5: 「Vary(Strong)」「Vary(Subtle)」を選択し、強弱2種類のバリエーションを生成し比較する。
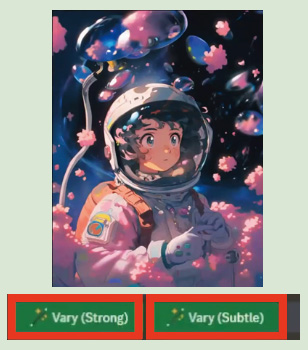
6: それぞれのバリエーションの画像を生成。Vary(Subtle)で生成した画像の中から「U4」を選択。


7: 「Upscale(4x)」で4倍にアップスケールし、niji・journeyでの工程は終了となる。
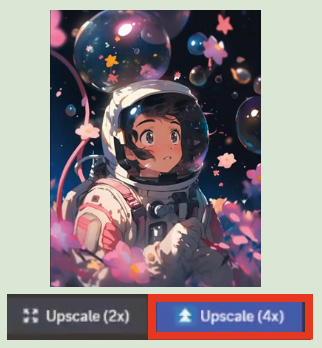
② 文字を載せて出来上がり!
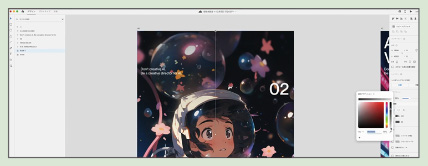
アドビXDを使ってデザインし、ポスターの完成。

① niji・journeyを使い、「都会の街並み」をテーマにアニメテイストの画像を生成。
1: Discordのプロンプト入力欄にプロンプトを入力しEnter。生成コマンド「/imagine」を入力し、「1girl,city,anime Cel shading」とプロンプトを入力。4種類の画像が生成される。
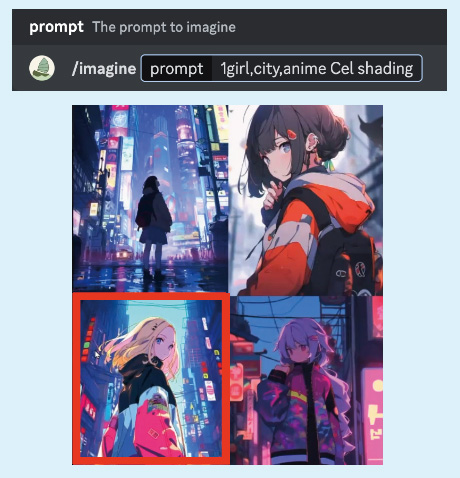
2: 左下の画像をベースに作り込むことを決定。「U3」をクリックし、高解像度の画像を生成。
3: 選択した画像がアップスケールされて生成される。「Zoom out 1.5x」をクリックし、引きの画像を生成する。
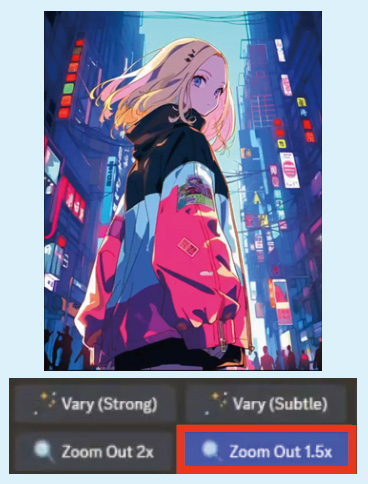
4: 1.5倍ズームアウトした画像を生成。左上の画像を使用するため「U1」を選択。

5: 「Upscale(4x)」で4倍にアップスケールし、niji・journeyでの工程は終了となる。

② 文字を載せて出来上がり!
